不知不觉博客已经荒废了快一年,实在惭愧。
近来公司redis新架构会升级到redis4,借机将拖欠已久的redis4新特性解析补上,至于redis5的特性恐怕要等架构公司再升级了吧:-)
新特性list
redis从3.2升级到4.0,有许多大的改动和优化点,本文主要从源码的角度分析新特性的实现 所有源码基于redis4.0
- psync2
- lfu
- lazy free
- aofrewrite优化
- rdb-aof混合持久化
- module
- memory命令
PSYNC2
fullsync
fullsync是redis最基础的主从同步机制,大致的流程为slave发送fullsync命令,master将内存中的数据dump成rdb文件,传输给slave,实现slave第一次从master同步数据,fullsync成功之后,master和slave会建立起一种特殊的client->server的通信机制,进行实时的增量数据同步
psync
只有fullsync的主从同步机制并不完善。当master和slave断开后,由于master和slave都没有保存同步的状态,slave只能重新进行fullsync。这在网络抖动时会造成很大的性能开销(主要是master rdb文件生成、传输,slave导入rbd文件)
redis在2.8时引入了部分同步机制psync,能够避免上述例子中主从秒断导致的fullsync。psync是基于backlog(命令缓冲区,定长的FIFO队列,默认1M)、 runId(实例运行的唯一标识)和offset(复制偏移量)实现的
当slave不是第一次进行主从同步时,slave会先尝试进行psync,如果slave的master runId和当前master保持一致,并且offset在backlog内,就会基于master的backlog中的数据进行psync
pysnc2
引入psync后,主从同步健壮了许多,大部分情况下这套机制能够比较好的运作。但在主从关系出现变化的情况下就无法正常进行psync(例如sentinel和rc的master故障自动切换)。因为从库的master runId就无法和新的master对应,导致触发fullsync;又或者当redis实例重启时,slave的master runId和offset也会丢失,也无法正常进行psync
而psync2就是针对上述两个问题进行了优化:
- redis4在原有server.replid的基础上添加了server.replid2,用于保存同步过的master run id
struct redisServer {
// ...
char replid[CONFIG_RUN_ID_SIZE+1]; /* My current replication ID. */
char replid2[CONFIG_RUN_ID_SIZE+1]; /* replid inherited from master*/
// ...
}
当发生主从关系变更时,被提升为master的slave会将之前的master run id记录到server.replid2中
void shiftReplicationId(void) {
memcpy(server.replid2,server.replid,sizeof(server.replid));
// ...
}
而psync在进行判断时,新增了replid2的校验
int masterTryPartialResynchronization(client *c) {
// ...
if (strcasecmp(master_replid, server.replid) &&
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset))
{
// ...
goto need_full_resync;
}
// ...
}
- redis4的psync2通过将replid、offset保存在rdb文件中,在节点重启时能够恢复主从同步信息,并尝试psync
int rdbSaveInfoAuxFields(rio *rdb, int flags, rdbSaveInfo *rsi) {
// ...
if (rsi) {
if (rdbSaveAuxFieldStrInt(rdb,"repl-stream-db",rsi->repl_stream_db)
== -1) return -1;
if (rdbSaveAuxFieldStrStr(rdb,"repl-id",server.replid)
== -1) return -1;
if (rdbSaveAuxFieldStrInt(rdb,"repl-offset",server.master_repl_offset)
== -1) return -1;
}
if (rdbSaveAuxFieldStrInt(rdb,"aof-preamble",aof_preamble) == -1) return -1;
return 1;
}
LFU
在4.0以前,redis的缓存淘汰机制主要有3大类:无差别、有过期时间缓存、lru,具体到配置有6种细化配置
而在redis4中增加了新添加了一种缓存淘汰机制,lfu(Least Frequently Used),和lru的实现一样,redis的lfu并不是精准的lfu淘汰策略,是基于概率的近似lfu
首先通过复用redisObject中的lru字段存储lfu的信息,lru字段总共24bit。作为lfu存储时,前16个bit用于存储最近一次访问的时间,后8bit用于存储lfu频次
#define LRU_BITS 24
#define OBJ_SHARED_REFCOUNT INT_MAX
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
那么redis4是如何通过这24bit进行lfu标识呢?16bit(0~65535)如何存储时间?8bit(0~255)如何存储频次?能否满足超高访问量的热key场景?
首先从redis key访问的逻辑开始看,当某个key被正常访问时,redis都会更新其lfu信息
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
if (server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
!(flags & LOOKUP_NOTOUCH))
{
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
}
return val;
} else {
return NULL;
}
}
counter衰减
updateLFU基本包含lfu的全部逻辑,首先会对访问次数counter进行衰减,然后对counter进行递增
void updateLFU(robj *val) {
unsigned long counter = LFUDecrAndReturn(val); // counter衰减
counter = LFULogIncr(counter); // counter递增
val->lru = (LFUGetTimeInMinutes()<<8) | counter; // 更新lfu信息
}
//counter的衰减值在大部分情况下等于上次到当前的时间分钟差
unsigned long LFUGetTimeInMinutes(void) {
return (server.unixtime/60) & 65535;
}
unsigned long LFUTimeElapsed(unsigned long ldt) {
unsigned long now = LFUGetTimeInMinutes();
if (now >= ldt) return now-ldt;
return 65535-ldt+now;
}
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;
unsigned long counter = o->lru & 255;
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
因为lfu字段只有16个bit用于存储上次访问时间(单位分钟),只能完整表示45.5天左右的时间,LFUGetTimeInMinutes在获取用于记录和比较的时间时也是只取了后16bit的数据,所以每过45天都会有一次时间差循环,所以当一个key在45天后才被再次被访问就无法准确描述其lfu时钟了
counter递增
lfu的递增操作就是纯粹基于概率的计算,在默认配置下可以支持百万量级的热key
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
上述代码转换成公式为1/((x-LFU_INIT_VAL)*server.lfu_log_factor+1),LFU_INIT_VAL默认为5,server.lfu_log_factor默认为10,默认配置下的概率分布图
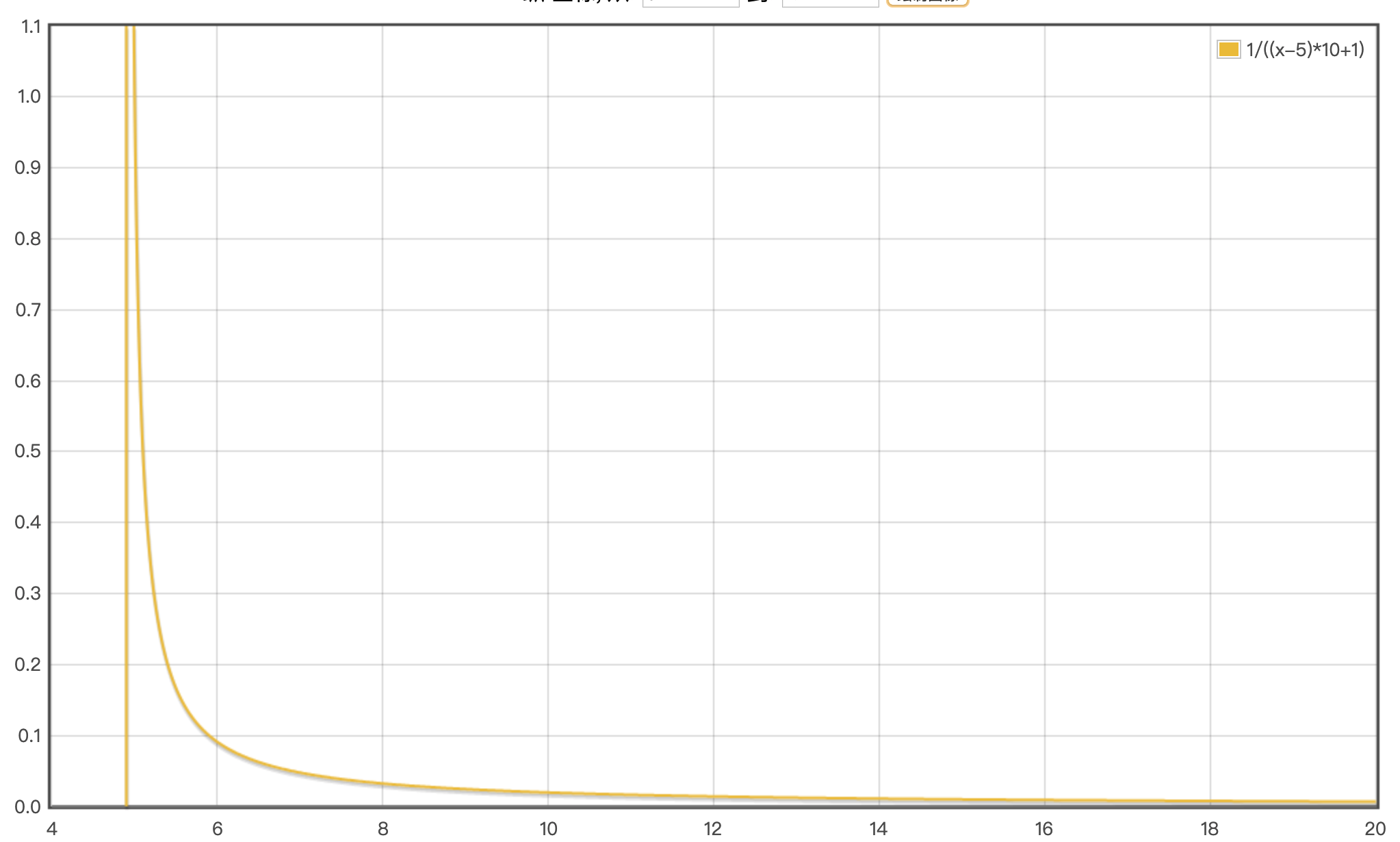
缓存淘汰
缓存淘汰的代码中也加入了lfu的逻辑分支,优先逐出掉lfu热度最低的key
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
// ...
for (j = 0; j < count; j++) {
unsigned long long idle;
// ...
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
idle = estimateObjectIdleTime(o);
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
idle = 255-LFUDecrAndReturn(o);
}
// ...
}
}
LAZY FREE
大key
由于redis在处理文件事件(网络请求)和时间事件时都是单线程,因此当有大key需要被删除或淘汰时都会阻塞主线程,而对于set、zset、hash、list的删除台套操作都需要遍历,时间复杂度O(n)
当然在明确了具体大key类型的场景下,client可以用scan等命令慢慢删除;但对于在线业务和自动过期被动删除等场景,就只能默默阻塞了
工作线程
redis严格意义上并不是一个单线程应用,除了在aofrewrite和rdbbgsave时会fork子进程外,还有3个工作线程bio,分别是用于AOF FD CLOSE、AOF FSYNC、LAZY FREE。其中LAZY FREE就是redis4新增的用于异步删除大key的工作线程
unlink
redis4新增了一个命令unlink,用于client异步删除大key
struct redisCommand redisCommandTable[] = {
// ...
{"unlink",unlinkCommand,-2,"wF",0,NULL,1,-1,1,0,0},
// ...
}
void unlinkCommand(client *c) {
delGenericCommand(c,1);
}
void delGenericCommand(client *c, int lazy) {
int numdel = 0, j;
for (j = 1; j < c->argc; j++) {
expireIfNeeded(c->db,c->argv[j]);
int deleted = lazy ? dbAsyncDelete(c->db,c->argv[j]) :
dbSyncDelete(c->db,c->argv[j]);
// ...
}
addReplyLongLong(c,numdel);
}
真实的异步删除逻辑在dbAsyncDelete中
#define LAZYFREE_THRESHOLD 64
int dbAsyncDelete(redisDb *db, robj *key) {
// `expires`的key和具体数据的key是同一个对象,要先删除`expires`的数据
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
dictEntry *de = dictUnlink(db->dict,key->ptr); // 对象从hash中删除
if (de) {
robj *val = dictGetVal(de);
size_t free_effort = lazyfreeGetFreeEffort(val); // 判断是否有必要使用工作线程异步删除
if (free_effort > LAZYFREE_THRESHOLD && val->refcount == 1) {
atomicIncr(lazyfree_objects,1); // lazyfree计数加一,用于info查看
bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL); // 创建异步删除任务
dictSetVal(db->dict,de,NULL); // 将db中的对象设为NULL
}
}
if (de) {
dictFreeUnlinkedEntry(db->dict,de); // 同步删除dict元素
if (server.cluster_enabled) slotToKeyDel(key); // 集群同步
return 1;
} else {
return 0;
}
}
其中unlink的逻辑就是将数据从db dict中去除,但并不真正free,然后将其返回。对于返回的大key,会通过lazyfreeGetFreeEffort返回n,当n大于64时,创建异步任务删除
size_t lazyfreeGetFreeEffort(robj *obj) {
if (obj->type == OBJ_LIST) {
quicklist *ql = obj->ptr;
return ql->len;
} else if (obj->type == OBJ_SET && obj->encoding == OBJ_ENCODING_HT) {
dict *ht = obj->ptr;
return dictSize(ht);
} else if (obj->type == OBJ_ZSET && obj->encoding == OBJ_ENCODING_SKIPLIST){
zset *zs = obj->ptr;
return zs->zsl->length;
} else if (obj->type == OBJ_HASH && obj->encoding == OBJ_ENCODING_HT) {
dict *ht = obj->ptr;
return dictSize(ht);
} else {
return 1; /* Everything else is a single allocation. */
}
}
FlushDB和FlushAll
FlushDB和FlushAll都会调用emptyDb,emptyDb通过getFlushCommandFlags函数判断是否需要进行异步,对于需要进行异步的命令会调用emptyDbAsync创建异步任务
int getFlushCommandFlags(client *c, int *flags) {
if (c->argc > 1) {
if (c->argc > 2 || strcasecmp(c->argv[1]->ptr,"async")) {
addReply(c,shared.syntaxerr);
return C_ERR;
}
*flags = EMPTYDB_ASYNC;
} else {
*flags = EMPTYDB_NO_FLAGS;
}
return C_OK;
}
void emptyDbAsync(redisDb *db) {
dict *oldht1 = db->dict, *oldht2 = db->expires;
db->dict = dictCreate(&dbDictType,NULL);
db->expires = dictCreate(&keyptrDictType,NULL);
atomicIncr(lazyfree_objects,dictSize(oldht1));
bioCreateBackgroundJob(BIO_LAZY_FREE,NULL,oldht1,oldht2);
}
过期和逐出
redis4新增了一个配置项server.lazyfree_lazy_expire,用于标识数据过期是否需要异步执行。在被动过期和主动过期的逻辑中也都加上了对应判断
int expireIfNeeded(redisDb *db, robj *key) {
// ...
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
int activeExpireCycleTryExpire(redisDb *db, dictEntry *de, long long now) {
long long t = dictGetSignedIntegerVal(de);
if (now > t) {
// ...
propagateExpire(db,keyobj,server.lazyfree_lazy_expire);
if (server.lazyfree_lazy_expire)
dbAsyncDelete(db,keyobj);
else
dbSyncDelete(db,keyobj);
// ...
return 1;
} else {
return 0;
}
}
针对逐出,lazy free的配置是server.lazyfree_lazy_eviction,同样也添加了异步删除逻辑
int freeMemoryIfNeeded(void) {
// ...
while (mem_freed < mem_tofree) {
// ...
/* Finally remove the selected key. */
if (bestkey) {
if (server.lazyfree_lazy_eviction)
dbAsyncDelete(db,keyobj);
else
dbSyncDelete(db,keyobj);
}
// ...
}
}
以及redis内部各种会涉及到删除key的逻辑(例如slot迁移),也增加了配置项server.lazyfree_lazy_server_del
lazyfree_lazy_server_del
int dbDelete(redisDb *db, robj *key) {
return server.lazyfree_lazy_server_del ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
RDB-AOF混合持久化
redis持久化
redis提供了两种持久化方案,一种是全量快照的rdb,还有一种是基于增量命令的aof。两种持久化方案各有各的优势
rdb数据紧凑、文件小、传输和数据恢复速度较快;但可能会丢失较多数据,且rdb文件基本不可读
aof文件基于增量命令,写入的也都是命令,可读性高,数据更完整;缺点是文件较大,会有大量无效历史命令,文件导入恢复速度慢于rdb
混合持久化
redis4综合了两种持久化方案,提供了一种混合持久化的方式,通过server.aof_use_rdb_preamble可以打开混合持久化。
混合持久化实现很简单,就是在aofrewrite的时候先将存量数据已rdb的形式写入文件,之后的增量数据都通过aof形式追加。持久化文件就是一个rdb+aof的混合数据文件。
int rewriteAppendOnlyFile(char *filename) {
// ...
if (server.aof_use_rdb_preamble) {
int error;
if (rdbSaveRio(&aof,&error,RDB_SAVE_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
// ...
}
同样在aof导入时,也增加了相应逻辑。由于rdb文件的开头是REDIS+rdb版本号,所以导入时可以根据其判断是否为混合文件
int loadAppendOnlyFile(char *filename) {
// ...
char sig[5]; /* "REDIS" */
if (fread(sig,1,5,fp) != 5 || memcmp(sig,"REDIS",5) != 0) {
/* No RDB preamble, seek back at 0 offset. */
if (fseek(fp,0,SEEK_SET) == -1) goto readerr;
} else {
/* RDB preamble. Pass loading the RDB functions. */
rio rdb;
serverLog(LL_NOTICE,"Reading RDB preamble from AOF file...");
if (fseek(fp,0,SEEK_SET) == -1) goto readerr;
rioInitWithFile(&rdb,fp);
if (rdbLoadRio(&rdb,NULL,1) != C_OK) {
serverLog(LL_WARNING,"Error reading the RDB preamble of the AOF file, AOF loading aborted");
goto readerr;
} else {
serverLog(LL_NOTICE,"Reading the remaining AOF tail...");
}
}
}
aofrewrite优化
原有逻辑
由于aof文件为命令增量追加,因此随着server运行时间的aof文件会越来越大,而有大量的历史命令其实是无效的,例如有过期时间的key、重复set。因此redis提供了aofrewrite命令通过fork子进程,对aof文件进行重写。
在redis4之前,aofrewrite的大致流程为fork子进程,子进程创建一个临时文件,将数据库中的数据转换为命令写入aof文件;而父进程在fork子进程之后会维护一个aofrewriteBuffer,将aofrewrite期间的命令进行缓存,在子进程执行完成退出后,父进程会将这些buffer统一写入到aof文件中,然后重命名临时文件。
但是当aofrewrite期间有大量写入的情况下,父进程在子进程rewrite完成后,需要将大量数据写入到文件中,这对于“单线程”的redis来说是致命的,很可能长时间阻塞正常的在线请求
优化
redis4添加了用于父进程和aofrewrite子进程通信的pipe,父进程在aofwrite期间会注册一个aofChildWriteDiffData文件事件,aofrewrite期间的增量命令会通过管道发送给子进程,在子进程中将大部分增量命令写入文件
此外还有用于通信的pipe,用于父进程和子进程之间的通信,子进程执行完成后父进程将剩下的增量命令写入文件,虽然主进程还需要写文件,但已经是少量可接受的
aofrewrite的主体函数为rewriteAppendOnlyFileBackground
int rewriteAppendOnlyFileBackground(void) {
// ...
if (aofCreatePipes() != C_OK) return C_ERR;
// ...
if ((childpid = fork()) == 0) {
char tmpfile[256];
/* Child */
closeListeningSockets(0);
redisSetProcTitle("redis-aof-rewrite");
snprintf(tmpfile,256,"temp-rewriteaof-bg-%d.aof", (int) getpid());
if (rewriteAppendOnlyFile(tmpfile) == C_OK) {
// ...
}
// ...
} else {
/* Parent */
// ...
}
return C_OK; /* unreached */
}
在fork之前,会先调用aofCreatePipes创建一条用于数据传输,两条用于控制的pipe,并且给server.aof_pipe_read_ack_from_child注册了一个读事件aofChildPipeReadable
int aofCreatePipes(void) {
int fds[6] = {-1, -1, -1, -1, -1, -1};
int j;
if (pipe(fds) == -1) goto error; /* parent -> children data. */
if (pipe(fds+2) == -1) goto error; /* children -> parent ack. */
if (pipe(fds+4) == -1) goto error; /* parent -> children ack. */
/* Parent -> children data is non blocking. */
if (anetNonBlock(NULL,fds[0]) != ANET_OK) goto error;
if (anetNonBlock(NULL,fds[1]) != ANET_OK) goto error;
if (aeCreateFileEvent(server.el, fds[2], AE_READABLE, aofChildPipeReadable, NULL) == AE_ERR) goto error;
server.aof_pipe_write_data_to_child = fds[1]; // 父进程写增量命令
server.aof_pipe_read_data_from_parent = fds[0]; // 子进程读取增量命令
server.aof_pipe_write_ack_to_parent = fds[3]; // 子进程写入消息
server.aof_pipe_read_ack_from_child = fds[2]; // 父进程读取子进程消息
server.aof_pipe_write_ack_to_child = fds[5]; // 父进程写入消息
server.aof_pipe_read_ack_from_parent = fds[4]; // 子进程读取父进程消息
server.aof_stop_sending_diff = 0;
return C_OK;
error:
serverLog(LL_WARNING,"Error opening /setting AOF rewrite IPC pipes: %s",
strerror(errno));
for (j = 0; j < 6; j++) if(fds[j] != -1) close(fds[j]);
return C_ERR;
}
子进程逻辑
子进程先关闭了socket的监听,然后调用rewriteAppendOnlyFile将db中的数据写入aof文件中
int rewriteAppendOnlyFile(char *filename) {
// ...
snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int) getpid());
fp = fopen(tmpfile,"w");
server.aof_child_diff = sdsempty();
rioInitWithFile(&aof,fp);
if (server.aof_rewrite_incremental_fsync)
rioSetAutoSync(&aof,AOF_AUTOSYNC_BYTES);
if (server.aof_use_rdb_preamble) {
int error;
if (rdbSaveRio(&aof,&error,RDB_SAVE_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
int nodata = 0;
mstime_t start = mstime();
while(mstime()-start < 1000 && nodata < 20) {
if (aeWait(server.aof_pipe_read_data_from_parent, AE_READABLE, 1) <= 0)
{
nodata++;
continue;
}
nodata = 0; /* Start counting from zero, we stop on N *contiguous*
timeouts. */
aofReadDiffFromParent();
}
/* Ask the master to stop sending diffs. */
if (write(server.aof_pipe_write_ack_to_parent,"!",1) != 1) goto werr;
if (anetNonBlock(NULL,server.aof_pipe_read_ack_from_parent) != ANET_OK)
goto werr;
if (syncRead(server.aof_pipe_read_ack_from_parent,&byte,1,5000) != 1
byte != '!') goto werr;
serverLog(LL_NOTICE,"Parent agreed to stop sending diffs. Finalizing AOF...");
aofReadDiffFromParent();
serverLog(LL_NOTICE,
"Concatenating %.2f MB of AOF diff received from parent.",
(double) sdslen(server.aof_child_diff) / (1024*1024));
if (rioWrite(&aof,server.aof_child_diff,sdslen(server.aof_child_diff)) == 0)
goto werr;
if (rename(tmpfile,filename) == -1) {
serverLog(LL_WARNING,"Error moving temp append only file on the final destination: %s", strerror(errno));
unlink(tmpfile);
return C_ERR;
}
// ...
}
- 首先子进程会以进程id为名创建一个临时aof文件,然后初始化rio和aof_child_diff
- 其中
server.aof_rewrite_incremental_fsync默认开启,每32MB会自动将数据刷盘,减小峰值延迟 server.aof_use_rdb_preamble用于开启rdb、aof混合持久化,该特性为4.0后加入的,持久化文件为全量的rdb数据+aof增量命令- 在写完aof文件后,子进程会尝试从
server.aof_pipe_read_data_from_parent读取数据,aofReadDiffFromParent会将从管道中读取的数据追加到server.aof_child_diff - 读取完成后,子进程会通过管道给父进程发送一个
!,通知父进程不要往管道里写数据,然后等待父进程回复!,最后将管道里可能存在的数据读出,然后统一写入aof文件中,重命名aof文件
父进程逻辑
而当aofrewite期间有写命令时,feedAppendOnlyFile会调用aofRewriteBufferAppend将命令写入buffer
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
// ...
if (server.aof_child_pid != -1)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
sdsfree(buf);
}
将命令写入buffer后,会在server.aof_pipe_write_data_to_child上注册一个文件写事件aofChildWriteDiffData
void aofRewriteBufferAppend(unsigned char *s, unsigned long len) {
// ...
if (aeGetFileEvents(server.el,server.aof_pipe_write_data_to_child) == 0) {
aeCreateFileEvent(server.el, server.aof_pipe_write_data_to_child,
AE_WRITABLE, aofChildWriteDiffData, NULL);
}
}
aofRewriteBufferAppend负责将buffer中的数据通过pipe发送给子进程,只有在server.aof_stop_sending_diff为1或buffer block为null时退出
void aofChildWriteDiffData(aeEventLoop *el, int fd, void *privdata, int mask) {
listNode *ln;
aofrwblock *block;
ssize_t nwritten;
UNUSED(el);
UNUSED(fd);
UNUSED(privdata);
UNUSED(mask);
while(1) {
ln = listFirst(server.aof_rewrite_buf_blocks);
block = ln ? ln->value : NULL;
if (server.aof_stop_sending_diff
!block) {
aeDeleteFileEvent(server.el,server.aof_pipe_write_data_to_child,
AE_WRITABLE);
return;
}
if (block->used > 0) {
nwritten = write(server.aof_pipe_write_data_to_child,
block->buf,block->used);
if (nwritten <= 0) return;
memmove(block->buf,block->buf+nwritten,block->used-nwritten);
block->used -= nwritten;
block->free += nwritten;
}
if (block->used == 0) listDelNode(server.aof_rewrite_buf_blocks,ln);
}
}
server.aof_stop_sending_diff在aofCreatePipes中被初始化为0,而父进程通过aofChildPipeReadable读事件从子进程接收消息,当收到!时会设为1,并且给子进程发送一个!表示ack
void aofChildPipeReadable(aeEventLoop *el, int fd, void *privdata, int mask) {
char byte;
UNUSED(el);
UNUSED(privdata);
UNUSED(mask);
if (read(fd,&byte,1) == 1 && byte == '!') {
serverLog(LL_NOTICE,"AOF rewrite child asks to stop sending diffs.");
server.aof_stop_sending_diff = 1;
if (write(server.aof_pipe_write_ack_to_child,"!",1) != 1) {
serverLog(LL_WARNING,"Can't send ACK to AOF child: %s",
strerror(errno));
}
}
aeDeleteFileEvent(server.el,server.aof_pipe_read_ack_from_child,AE_READABLE);
}
父进程会在每次serverCron调用wait3回收子进程,对于aofrewrite子进程会在backgroundRewriteDoneHandler进行收尾工作
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
if (pid == -1) {
// ...
} else if (pid == server.rdb_child_pid) {
// ...
} else if (pid == server.aof_child_pid) {
backgroundRewriteDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else {
// ...
}
updateDictResizePolicy();
closeChildInfoPipe();
}
MEMORY
redis4新增了memory命令,用于内存分析,包含key-val,redis实例运行内存,jemalloc等 源码没啥好看的,命令比较繁琐,偷懒贴个链接:https://yq.aliyun.com/articles/278910
Module
redis虽然定位是一个key-val数据库,但社区一直有各种各样的骚操作,例如基于redis的全文搜索https://github.com/RedisLabsModules/RediSearch,在没有module前,大多是通过直接修改redis源码实现
redis4提供了module,定义了一些接口,只要根据接口就能自己编写第三方模块,通过module load将编译好的so文件导入到redis实例中 因此各种骚操作也基本迁移到moudle,感兴趣可以去官方module库学习一波
举个栗子
redis源码中提供了一些module示例,在src/module目录下,直接编译就能导入尝试玩耍;以其中helloword.c的hello.simple为例
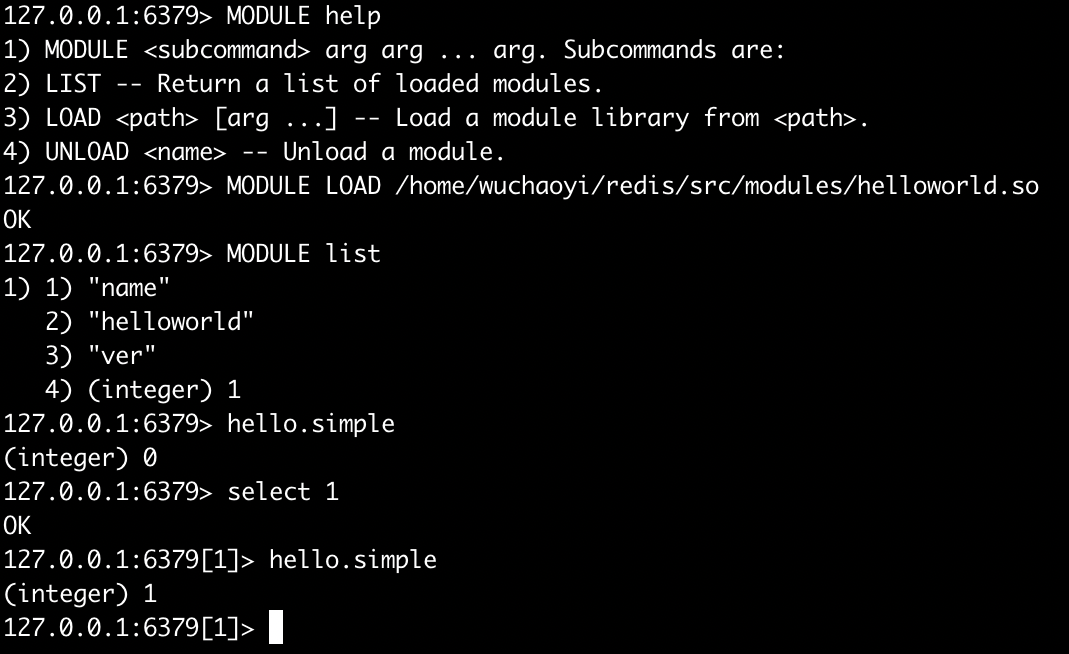
hello.simple实现的功能很简单,就是返回当前选中的db index
int HelloSimple_RedisCommand(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
REDISMODULE_NOT_USED(argv);
REDISMODULE_NOT_USED(argc);
RedisModule_ReplyWithLongLong(ctx,RedisModule_GetSelectedDb(ctx));
return REDISMODULE_OK;
}
自定义module
自定义module很简单,只需要将redismodule.h导入,并实现RedisModule_OnLoad函数,然后编译成.so动态库,导入即可
还是以源码中的例子helloword.c为例,首先调用了RedisModule_Init进行module的注册和初始化,然后通过RedisModule_CreateCommand进行命令注册映射。
int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
if (RedisModule_Init(ctx,"helloworld",1,REDISMODULE_APIVER_1)
== REDISMODULE_ERR) return REDISMODULE_ERR;
/* Log the list of parameters passing loading the module. */
for (int j = 0; j < argc; j++) {
const char *s = RedisModule_StringPtrLen(argv[j],NULL);
printf("Module loaded with ARGV[%d] = %s\n", j, s);
}
if (RedisModule_CreateCommand(ctx,"hello.simple",
HelloSimple_RedisCommand,"readonly",0,0,0) == REDISMODULE_ERR)
return REDISMODULE_ERR;
// ...
return REDISMODULE_OK;
}
module实现
redis为module提供了很多api,包括底层和命令层api,RedisModule_CreateCommand就是其中之一,在RedisModule_Init中,会将所有api导入。而每个api命名都是RedisModule_#name:
#define REDISMODULE_GET_API(name) \
RedisModule_GetApi("RedisModule_" #name, ((void **)&RedisModule_ ## name))
static int RedisModule_Init(RedisModuleCtx *ctx, const char *name, int ver, int apiver) {
void *getapifuncptr = ((void**)ctx)[0];
RedisModule_GetApi = (int (*)(const char *, void *)) (unsigned long)getapifuncptr;
REDISMODULE_GET_API(Alloc);
REDISMODULE_GET_API(Calloc);
REDISMODULE_GET_API(Free);
REDISMODULE_GET_API(Realloc);
REDISMODULE_GET_API(Strdup);
REDISMODULE_GET_API(CreateCommand);
// ...
if (RedisModule_IsModuleNameBusy && RedisModule_IsModuleNameBusy(name)) return REDISMODULE_ERR;
RedisModule_SetModuleAttribs(ctx,name,ver,apiver);
return REDISMODULE_OK;
}
在redis启动的时候,会对module进行初始化和api注册:
#define REGISTER_API(name) \
moduleRegisterApi("RedisModule_" #name, (void *)(unsigned long)RM_ ## name)
void moduleRegisterCoreAPI(void) {
server.moduleapi = dictCreate(&moduleAPIDictType,NULL);
REGISTER_API(Alloc);
REGISTER_API(Calloc);
REGISTER_API(Realloc);
REGISTER_API(Free);
REGISTER_API(Strdup);
REGISTER_API(CreateCommand);
// ...
}
通过上述逻辑可以看出module中的RedisModule_xxx函数最终都是对应到module.c中的RM_xxx,所以RedisModule_CreateCommand对应的函数RM_CreateCommand
int RM_CreateCommand(RedisModuleCtx *ctx, const char *name, RedisModuleCmdFunc cmdfunc, const char *strflags, int firstkey, int lastkey, int keystep) {
int flags = strflags ? commandFlagsFromString((char*)strflags) : 0;
if (flags == -1) return REDISMODULE_ERR;
if ((flags & CMD_MODULE_NO_CLUSTER) && server.cluster_enabled)
return REDISMODULE_ERR;
struct redisCommand *rediscmd;
RedisModuleCommandProxy *cp;
sds cmdname = sdsnew(name);
/* Check if the command name is busy. */
if (lookupCommand(cmdname) != NULL) {
sdsfree(cmdname);
return REDISMODULE_ERR;
}
cp = zmalloc(sizeof(*cp));
cp->module = ctx->module;
cp->func = cmdfunc;
cp->rediscmd = zmalloc(sizeof(*rediscmd));
cp->rediscmd->name = cmdname;
cp->rediscmd->proc = RedisModuleCommandDispatcher;
cp->rediscmd->arity = -1;
cp->rediscmd->flags = flags | CMD_MODULE;
cp->rediscmd->getkeys_proc = (redisGetKeysProc*)(unsigned long)cp;
cp->rediscmd->firstkey = firstkey;
cp->rediscmd->lastkey = lastkey;
cp->rediscmd->keystep = keystep;
cp->rediscmd->microseconds = 0;
cp->rediscmd->calls = 0;
dictAdd(server.commands,sdsdup(cmdname),cp->rediscmd);
dictAdd(server.orig_commands,sdsdup(cmdname),cp->rediscmd);
return REDISMODULE_OK;
}
RM_CreateCommand大部分都是初始化和校验,其中最关键的两行是22、31行,将RedisModuleCommandDispatcher作为命令真实方法注册到了server.commands中
在RedisModuleCommandDispatcher中统一对命令进行处理执行
void RedisModuleCommandDispatcher(client *c) {
RedisModuleCommandProxy *cp = (void*)(unsigned long)c->cmd->getkeys_proc;
RedisModuleCtx ctx = REDISMODULE_CTX_INIT;
ctx.module = cp->module;
ctx.client = c;
cp->func(&ctx,(void**)c->argv,c->argc);
moduleHandlePropagationAfterCommandCallback(&ctx);
moduleFreeContext(&ctx);
}
更细致的执行过程和数据结构定义就懒得解析了,都是大同小异 0.0~。
让我们回到module load,该命令最终会调用到moduleLoad
moduleLoad中通过dlopen尝试加在动态链接库,并通过dlsym获取RedisModule_OnLoad函数,然后将client的参数传入调用,成功后将handle添加到全局的modules dict中
int moduleLoad(const char *path, void **module_argv, int module_argc) {
int (*onload)(void *, void **, int);
void *handle;
RedisModuleCtx ctx = REDISMODULE_CTX_INIT;
handle = dlopen(path,RTLD_NOW|RTLD_LOCAL);
if (handle == NULL) {
serverLog(LL_WARNING, "Module %s failed to load: %s", path, dlerror());
return C_ERR;
}
onload = (int (*)(void *, void **, int))(unsigned long) dlsym(handle,"RedisModule_OnLoad");
if (onload == NULL) {
serverLog(LL_WARNING,
"Module %s does not export RedisModule_OnLoad() "
"symbol. Module not loaded.",path);
return C_ERR;
}
if (onload((void*)&ctx,module_argv,module_argc) == REDISMODULE_ERR) {
if (ctx.module) {
moduleUnregisterCommands(ctx.module);
moduleFreeModuleStructure(ctx.module);
}
dlclose(handle);
serverLog(LL_WARNING,
"Module %s initialization failed. Module not loaded",path);
return C_ERR;
}
/* Redis module loaded! Register it. */
dictAdd(modules,ctx.module->name,ctx.module);
ctx.module->handle = handle;
serverLog(LL_NOTICE,"Module '%s' loaded from %s",ctx.module->name,path);
moduleFreeContext(&ctx);
return C_OK;
}
SWAPDB
一个比较有意思的小功能,用于交换DB,由于DB在redis内部为指针array,因此swapDB为简单指针交换的O(1)操作,但是因为block_keys是跟DB关联的,所以还需要将block_keys进行互换
例如可以无侵入、无感知切换在线服务的redis数据
int dbSwapDatabases(int id1, int id2) {
if (id1 < 0
id1 >= server.dbnum
id2 < 0
id2 >= server.dbnum) return C_ERR;
if (id1 == id2) return C_OK;
redisDb aux = server.db[id1];
redisDb *db1 = &server.db[id1], *db2 = &server.db[id2];
db1->dict = db2->dict;
db1->expires = db2->expires;
db1->avg_ttl = db2->avg_ttl;
db2->dict = aux.dict;
db2->expires = aux.expires;
db2->avg_ttl = aux.avg_ttl;
scanDatabaseForReadyLists(db1);
scanDatabaseForReadyLists(db2);
return C_OK;
}