近来参加了部门举办的接口性能挑战大赛,导致redis源码的博客一直没有更新。不过收获颇丰,特作此小结。
比赛介绍
规则
规则比较简单,根据提供的基础数据,实现一个http查询接口,返回内容为json且格式固定。在100并发、5000总请求下保证数据正确性,QPS高者胜。
禁⽌使⽤Load balance,在自己的开发机搭建单机服务。
开发机的配置为:单核cpu、4G内存、40G磁盘
基础数据
基础数据的格式如下:
id user_name npc_unique_string sex extra
1 超哥 e0f9fc3abcf2ecf3b016b6c991a05713 0 tlptWorxtd9aS1rBEyjMmUWo6Iz8anWtl1psE6xGquWVs3oKbi7W91lOD1hiGONvlPyIpROR1kUuZJTjNsmCC2tDfeT45Jus9rjD
总计4000W行、5.8G。
数据预处理
由于开发机只有4G的内存,扣除一些系统的内存以及服务运行的基础内存可用的就只剩3.5G左右。没法把完整的数据存入内存中,如果走文件io的话必然会拖慢响应速度。内存io是ns级别的、而磁盘io会到ms级别,这中间差了两个量级!
常见的计算机响应速度可见: http://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html
很明显,服务的性能瓶颈在于文件io。那么是否能进行数据压缩呢,将尽可能多的数据放入内存,尽量少走文件io?
基础数据分析
首先对基础数据进行分析:
id:是一个非连续的递增正整数,从10000048到1209899435,用4byte的unsigned int绰绰有余,由于数据是用文件交互,因此都是按照字符存储,转为数字已经压缩了50%,但是没什么进一步压缩的余地。user_name:是一个2~4个中文组成的,会占用6-12个byte,常用汉字就几千个,如果根据数据建立汉字map,有一定的压缩空间npc_unique_string:是一个MD5值,MD5值的本质是一个16进制数,每一位实际上只需要4bit就足够存储,因此能将原数据压缩一半sex:只有0和1两种可能,用一个单独的char保存有点奢侈了,由于id最大只有1209899435,可以将sex保存在id的高位extra:是一个由数字和大小写字母组成的100位字符串,所有的数字加大小写字母只有62种可能,用6bit就能枚举完,能压缩4分之1
除了user_name的压缩需要遍历具体数据外,其他的压缩策略都比较清晰了。
user_name是按照正常的中文姓名的方式来进行随机生成。因此在这个基础上我做了简单的分词,将4个字的前两个字判断为姓,也作为汉字map的枚举值,那么一个user_name用2或3个整数就能表示,如果所有汉字组合的枚举值小于1024,只需用一个unsigned int就能完整存储了!
遍历4000W行数据后,发现出题人东哥略懒,居然只有631种汉字枚举值组合,一个user_name直接压缩到4个byte。
至此,基础的数据结构已经能确定了:
typedef struct data_entry {
unsigned int id; // 4byte
unsigned int user_name; // 4byte
unsigned int npc_unique_string[4]; // 16byte
char sex; // 1byte
unsigned char extra[75]; // 75byte
} data_entry;
这里没有将sex按照预定方案存储是因为内存对齐,除sex外需要99byte,但是实际malloc申请内存的时候还是100byte,这多的1byte直接拿来存储sex恰到好处。通过上述针对性的压缩策略,将原本平均一行155byte的数据压缩到了100byte。
压缩脚本
由于压缩脚本只需要跑一次就够了,无需care执行效率,因此直接用php编写了一个压缩脚本。
主要的处理流程分为4部分
public function run()
{
$this->_handleWordMap($this->handle_file); // 统计汉字map
$row_generator = $this->_fileParse($this->handle_file, $this->fields_map);
$count = 0;
if (is_file($this->root_path . 'real_handle_data')) {
unlink($this->root_path . 'real_handle_data');
}
foreach ($row_generator as $row) {
$handle_row = [];
$handle_row['id'] = $row['id'] | ($row['sex'] * (2147483648)); // id和sex
$handle_row['user_name'] = $this->_handleUserName($row['user_name']); // 根据汉字map压缩user_name
$handle_row['npc_unique_string'] = $this->_handleNpcString($row['npc_unique_string']); // 压缩npc_string
$handle_row['extra'] = $this->_handleExtra($row['extra']); // 压缩extra
file_put_contents($this->root_path . 'real_handle_data', implode(' ', $handle_row) . "\n", FILE_APPEND);
if ($count++ % 10000 == 0) {
echo 'handle progress: ' .$count . PHP_EOL;
}
}
}
在压缩user_name之前先需要遍历一下原始数据,生成一个汉字的map
/**
* 处理用户名 生成字典
* @param $file_name
*/
private function _handleWordMap($file_name)
{
echo 'handle word map';
$count = 0;
$row_generator = $this->_fileParse($file_name, $this->fields_map);
foreach ($row_generator as $row) {
$i = 0;
$user_name = $row['user_name'];
$len = mb_strlen($user_name, 'utf8');
if ($len == 4) { // 4个字的user_name 将前两个字切分出来
$word = mb_substr($user_name, 0, 2, 'utf8');
if (!in_array($word, $this->word_map)) {
$this->word_map[] = $word;
echo $word . ' ';
}
$i = 2;
}
for (; $i < $len; $i++) { // 正常处理
$word = mb_substr($user_name, $i, 1, 'utf8');
if (!in_array($word, $this->word_map)) {
$this->word_map[] = $word;
echo $word . ' ';
}
}
if ($count++ % 10000 == 0) {
echo 'handle progress: ' .$count . PHP_EOL;
}
}
echo PHP_EOL . 'word_map_count:' . count($this->word_map) . PHP_EOL;
file_put_contents($this->root_path . 'word_map', implode(' ', $this->word_map) . "\n");
}
有了汉字map之后利用迭代器一行一行遍历原数据,生成压缩处理数据
/**
* 处理用户名
* @param $user_name
* @return false|int|string
*/
private function _handleUserName($user_name)
{
$user_name_num = 0;
$len = mb_strlen($user_name, 'utf8');
for ($i = 1; $i <= $len; $i++) {
if ($i == 3) { // 当user_name长度大于等于3 处理姓
$word = mb_substr($user_name, 0, $len - $i + 1, 'utf8');
$index = array_search($word, $this->word_map, true) + 1; // 由于不确定字符长度 0值空缺 解析时判0即可
$user_name_num = $index + ($user_name_num << 10);
break;
} else {
$word = mb_substr($user_name, $len - $i, 1, 'utf8');
$index = array_search($word, $this->word_map, true) + 1;
$user_name_num = $index + ($user_name_num << 10);
}
}
return $user_name_num;
}
/**
* 处理npc字符串 将字符串转换为数字
* @param $npc_unique_string
* @return string
*/
private function _handleNpcString($npc_unique_string)
{
$npc_nums[] = 0;
$npc_len = strlen($npc_unique_string);
for ($i = 1, $j = 0; $i <= $npc_len; $i++) {
$k = array_search($npc_unique_string[16 * $j + 8 - $i], $this->md5_char_map, true);
$npc_nums[$j] = ($npc_nums[$j] << 4) + $k;
if ($i % 8 == 0 && $i < $npc_len) {
$npc_nums[++$j] = 0;
}
}
return implode(' ', $npc_nums);
}
/**
* 处理extra字符串
* @param $extra
* @return string
*/
private function _handleExtra($extra)
{
$extra_nums[] = 0;
$extra_len = strlen($extra);
$temp_num = 0;
for ($i = 0, $j = 0; $i < $extra_len;) {
$k = array_search($extra[$i++], $this->full_char_map, true);
$k_map[] = $k;
$temp_num = ($temp_num << 6) + $k;
if (($i & 3) == 0) {
$extra_nums[$j++] = $temp_num >> 16;
$extra_nums[$j++] = ($temp_num >> 8) & 255;
$extra_nums[$j++] = $temp_num & 255;
$temp_num = 0;
}
}
return implode(' ', $extra_nums);
}
user_name和npc_string都是逆序处理,主要是为了读取解析的时候能够按照正常的逻辑正序处理。
其中user_name和npc_string的处理都差不多,主要是将字符串转换为unsigned int,因为用unsigned int压缩存储这两个值不会造成浪费。
例如一个npc_string的前8位为1234abcd,对应的枚举值分别为1、2、3、4、10、11、12、13。处理过程为(((13*16+12)*16)+15...),最终可以得到3703194401,就是前8个字符从高位开始的压缩结果。通过这样的压缩方法将32位的user_name压缩到4个unsigned int中。user_name类似,只不过是把枚举值改为了预处理的得到的汉字map,并压缩到一个unsigned int中。
extra的处理稍有点不同,因为extra的枚举有62种,需要用6个bit来枚举,如果用unsigned int或者unsigned long存储,空间利用率都不能达到百分之百,压缩效率只能达到百分之80,所以采用了更小的unsigned char进行存储。
因为一个字符需要6个bit,每3个unsigned char能存储4个字符。在逻辑处理的时候,将每3个unsigned char可以看做是一个24bit长的2进制数,每6bit划分一个字符。例如前4个字符为1aAB,对应的枚举值分别为1、10、36、37,将这四个值按照之前的方法,每6bit存储一个值,可以得到305445。将这个数字拆分成3个unsigned char,4、169、37。通过这种压缩方法,可以将100位的extra压缩到75个unsigned char中。
在答辩的时候有一位算法老司机问试过哈夫曼编码否?不可否认哈夫曼编码是一种很好的编码方法,但是并不适用于该场景。因为extra和npc_string的字符都是随机生成的,每个字符出现的概率基本上是相等的,而哈夫曼的本质是不定长编码,将概率大的枚举值设为短编码,从而使平均编码长度缩小。而在概率均等的情况下,哈夫曼编码就失去了优势,甚至还需要浪费额外的空间对编码长度进行维护。而user_name可能有一定的枚举值概率偏移,但会大大增加代码的复杂性,并且由于内存对齐,哪怕能缩短平均编码长度,但是还是需要同样大小的内存进行存储。
存储数据结构选择
首先由于数据有4000W条,哪怕已经压缩到了100byte,也需要3.7G的内存,无法完整塞入内存中。因此采用了一种混合存储的方案,将大部分的数据存储到内存中,剩余保存不下的数据通过建立文件偏移量索引的方式,进行保存。也就是每一个id对应一个fseek值,单个节点只需要8byte即可。
查询条件只有id,当请求打到服务的时候,根据一个id的极值进行判断走文件索引还是直接读取内存中的完整数据即可。
在这种混合存储的方案下,理想情况3.5G存储情况为:3700W条压缩数据+300W条文件索引,3700W*108+300W*8=3.46G。
在这种方案下,我尝试了两种存储方案,分别是hash和连续的顺序存储。
hash
hash算法是通过关键码值映射到表中的一个位置进行数据访问,以加快查询速度。具体的详可以参考:从头到尾解析Hash表算法
最开始考虑的存储数据结构的就是hash表,主要是因为hash表的查询效率为O(1),能够根据id快速查找到对应的数据。由于采用的是拉链法解决hash冲突,每个节点都需要多8个byte的next指针,数据结构变成了:
typedef struct data_entry {
unsigned int id; // 4byte
unsigned int user_name; // 4byte
unsigned int npc_unique_string[4]; // 16byte
char sex; // 1byte
unsigned char extra[75]; // 75byte
struct data_entry * next; // 8byte
} data_entry;
typedef struct file_index { // 文件索引结构
unsigned int id;
unsigned int fseek;
struct file_index * next;
} file_index;
4000W行数据比之前的理想多需要300M,除此之外还需要维护巨大的两个hash表结构。为了方便操作、提高hash表利用率,将hash表的大小设为比存储数据量小的最大的2的次幂。这样只能存储2200W条完整数据加上1800W条文件索引。空间利用率不够,查询效率带来的提升完全无法弥补文件io的开销。
顺序连续存储
而连续存储的空间利用率可以达到百分之百,如果在连续的内存空间中进行存储,就能达到理想情况的预期了。连续存储首先需要有序,而基础数据本身已经根据id排好序,无需预处理就可以直接用了。在查找的时候通过二分查找,最多可能的查找次数为26次,但是由于是在内存中进行查找相比起文件io的开销已经足够快了。
在这种方案下,基础的数据结构稍有变化,将每个数据的id统一保存到索引结构中:
typedef struct data_entry { // 压缩数据不保存id 96byte
unsigned int user_name; // 4
unsigned int npc_unique_string[4]; // 16
char sex; // 1
unsigned char extra[75]; // 75
} data_entry;
#define DATA_NUM 40000000
#define HANDLE_NUM 37000000
#define FILE_INDEX_NUM 3000000
data_index = malloc(DATA_NUM * sizeof(unsigned int)); // 索引保存了id
datas = (struct data_entry *)malloc(HANDLE_NUM * sizeof(*entry)); // 完整数据
fseeks = malloc(FILE_INDEX_NUM * sizeof(unsigned int)); // 文件索引
data_index是一个4000W行的索引,每行都保存了一个unsigned int的id。完整数据和文件索引也是连续存储的,其地址的偏移量与data_index保持一致。当有请求打到服务时,先通过data_index进行二分查找,找到偏移量,根据请求id的大小判断是走文件还是直接读取完整数据,再利用偏移量找到数据返回。
通过这个方案达成了预定理想的方案,3700W的完整数据在内存,300W的数据为文件索引,没有内存空间浪费!
网络模型
虽然这次的重点在数据处理和压缩上,但是网络模型还是有一定的优化空间的。
首先这次的请求都是短连接,没有连接复用的场景,没法用epoll等IO复用模型了,于是乎采用了最简单的阻塞socket。
但由于数据无法完整的存入内存,还是会有部分文件io。哪怕是少量的文件io也会长时间阻塞server,解决方案就是采用线程池。
线程池
之所以采用多线程,而不是多进程还是因为进程稍微重了一点,开销较大,只是一个比赛并不需要长时间运行,不用太care安全性。
最开始只是简单的来一个请求phread_create一个进程,但是进程的创建和销毁也有一定的开销,影响了QPS,因此通过线程池预先申请了100个线程,每个请求被主线程accpet后直接创建一个任务到任务队列中,交由线程池处理。
100个线程是对应client的100并发设定的一个值。
while(1)
{
// init
socket_fd = (int *)malloc(sizeof(int)); // 在堆上单独申请一个fd
// accept
*socket_fd = accept(listen_fd, NULL, NULL);
// add worker
pool_add_worker(request_handle, socket_fd); // 将请求的fd添加到任务队列中
}
多线程不能共用一个基础数据的fd,否则在并发的情况下可能会出现被一个线程fseek再被另一个线程read情况。需要提前打开100个fd
for (i = 0; i < THREAD_NUM; i++) { // 提前open文件
origin_fd[i] = fopen("/tmp/data", "r");
}
在通过文件索引读取的时候,通过请求计数确定对应线程使用的fd。
而线程池的大致原理就是在线程初始化的时候在将一个特定的函数注册到每个线程中,这个函数中对应的线程监听任务队列,一旦任务队列长度不为0就出队一个任务,而任务的数据结构中包括了真实的处理函数和对应参数。在使用的时候只需要不停的往任务队列中添加任务即可。
具体的线程池代码就不进行详解了,毕竟是从网上copy过来改了改的。
参数调整
除了线程池外,还对socket的参数进行了一些调整。例如禁用了Nagle算法、根据带宽调整了一下send buf和rev buf。主要是参考了http://blog.csdn.net/runboying/article/details/7206277
请求处理
请求处理主要分为3个部分:HTTP请求解析和响应、数据查找和数据解析。
HTTP请求
其实这个server并没有完整的实现HTTP的解析,只是针对比赛规则对get参数中的id进行了解析,在返回的时候也只是返回了必要的头信息。
// skip method
while (!isspace((int)read_buf[i++]));
while (isspace((int)read_buf[++i]));
handle_line(i, j, read_buf, url); // handle url
query_string = url;
while ((*query_string != '=') && (*query_string != '\0'))
query_string++;
*query_string = '\0';
query_string++;
uatoi(query_string, id_num, j);
handle_line是自定义的宏,主要是将read_buf中的内容复制到url中。
在解析http请求的时候,跳过了method的解析,直接解析url参数,并将get参数的第一个值直接赋值给id_num。uatoi也是自定义的宏,主要是将字符串转换成unsigned int。
返回的数据也是去除了不必要的数据,并没有严格按照HTTP协议
sprintf(buf, "HTTP/1.1 200 OK\r\nAuthor: carachao\r\n\r\n{\"data\":{\"id\":\"%u\",\"user_name\":\"%s\",\"npc_unique_string\":\"%s\",\"sex\":\"%c\",\"extra\":\"%s\"}}", id_num, tmp_user_name, npc_unique_string, sex, extra);
send(fd, buf, strlen(buf), 0);
通过完全定制化的HTTP解析,尽量节省了部分不必要的开销和网络传输。
数据查找
就是简单的二分查找,没什么特别的
// find
low = 0;
high = DATA_NUM - 1;
hash_index = -1;
if (id_num < data_index[low] || id_num > data_index[high]) { // 边界判断
high = -1;
}
while (low <= high) { // 二分查找
mid = (low + high) / 2;
if (id_num > data_index[mid]) {
low = mid + 1;
} else if (id_num < data_index[mid]){
high = mid - 1;
} else {
hash_index = mid;
break;
}
}
数据解析
if (likely(hash_index != -1)) {
// 解析数据
}
} else {
sprintf(buf, "HTTP/1.1 200 OK\r\nAuthor: czrzchao\r\n\r\n{\"data\":{}}");
}
如果查找到了数据,有两种情况:在内存数据范围内、需要通过文件索引走文件io
如果在内存的数据范围内,需要将对应的数据进行解码。
tmp_user_name = malloc(14*sizeof(char));
// decode user_name
user_name_num = data_hash[hash_index].user_name;
cur_len = 0;
while (1) {
char_index = user_name_num & 1023;
str_len = strlen(word_map[char_index]);
memcpy(tmp_user_name + cur_len, word_map[char_index], str_len);
cur_len += str_len;
user_name_num = user_name_num >> 10;
if (user_name_num == 0) {
tmp_user_name[cur_len] = '\0';
break;
}
}
// decode npc_unique_num
for (i = 0, j = 0; i < 4; i++) {
npc_unique_num = data_hash[hash_index].npc_unique_string[i];
while (1) {
npc_unique_string[j++] = md5_char_map[npc_unique_num & 15];
if (!(j & 7)) {
break;
}
npc_unique_num = npc_unique_num >> 4;
}
}
npc_unique_string[j] = '\0';
// decode extra_num
for (i = 0, j = 0; i < 75; i = i+3) {
extra_num = (data_hash[hash_index].extra[i] << 16) + (data_hash[hash_index].extra[i+1] << 8) + (data_hash[hash_index].extra[i+2]);
extra[j++] = full_char_map[extra_num >> 18];
extra[j++] = full_char_map[(extra_num & 258048) >> 12];
extra[j++] = full_char_map[(extra_num & 4032) >> 6];
extra[j++] = full_char_map[extra_num & 63];
}
extra[j] = '\0';
在解析user_name的时候,每10位表示一个枚举值。因为汉字map从1开始,通过0值来判断是否解析完成,解决了名字不定长的问题。
npc_string同user_name,每4位表示一个枚举值,每个unsigned int保存了8个字符枚举值。
extra_num略有不同,需要在映射解析之前,将每3个unsigned char拼接成一个数字,然后每6位解析成一个字符枚举值。
如果需要走文件,首先需要根据已处理文件请求cout找到对应的fd,避免和其他线程冲突。这里没有用加锁的机制,主要还是因为场景单一,这样实现起来代码复杂度低。最后根据对应的fseek读取一行数据解析即可。
char tmp_user_name[15];
FILE * origin_file = origin_fd[handle_file_count % THREAD_NUM];
char file_buffer[CONTENT_SIZE];
// decode user_name
i = 0;
fseek(origin_file, fseeks[hash_index-HANDLE_NUM], SEEK_SET);
fgets(file_buffer, CONTENT_SIZE, origin_file);
handle_line(i, j, file_buffer, tmp_unsigned_int_char); // handle id
handle_line(i, j, file_buffer, tmp_user_name); // handle tmp_user_name
handle_line(i, j, file_buffer, npc_unique_string); // handle npc_unique_string
sex = file_buffer[i];
while (!isspace((int)file_buffer[i++]));
handle_line(i, j, file_buffer, extra); // handle extra
小结
这一次的性能大赛实际上尝试了很多种方案,包括用swap区保存4000W条数据、单线程、每次请求都创建线程、以及上面的两种方案。很多东西都是靠打日志一点一点试出来的,效率并不高。在答辩的时候,评委顾老师说既然是性能大赛,第一件事应该是搭建性能分析的工具,而不是直接实现。这还是相当有指导性的,虽然这次比赛最终还是没能搭一个性能分析的工具( Unix下C编程基础还是太差了:( ),但这个思想还是以后要铭记的,磨刀不误砍柴工!
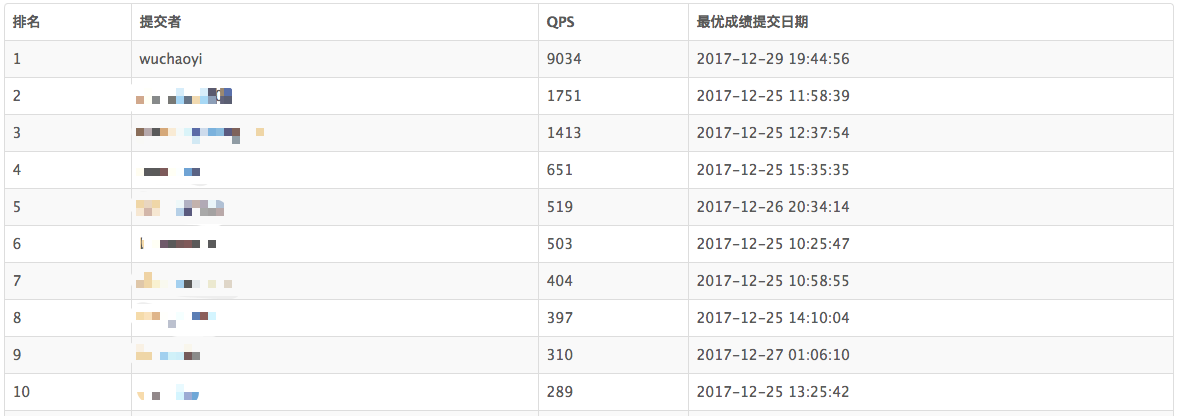
最后附上装逼排行图