近来在研读redis3.2.9的源码,虽然网上已有许多redis的源码解读文章,但大都不成系统,且纸上学来终觉浅,遂有该系列博文。部分知识点参照了黄建宏的《Redis设计与实现》。
前言
本文探究的数据结构并不是 redis 对外暴露的5种数据结构,而是redis内部使用的基础数据结构,这些基础的数据结构 redis 不仅和 redisObj 一起构成了对外暴露的5种数据结构,还被运用于 redis 内部的各种存储和逻辑交互,支撑起了 redis 的运行。
redis 的基础数据结构主要有以下7种:
- SDS(simple dynamic string):简单动态字符串
- ADList(A generic doubly linked list):双向链表
- dict(Hash Tables):字典
- intset:整数结合
- ziplist:压缩表
- quicklist:快速列表(双向链表和压缩表二合一的复杂数据结构)
- skiplist:跳跃链表
skiplist
跳跃表是一种有序的数据结构,可以快速查找对应的元素,查找、删除和插入的平均效率为 O(logN) 。redis 用跳跃表来实现hash和zset。
跳跃表简介
简单的说跳跃表就是在一个有序的集合上加上多层节点,每层节点都是在下层节点的基础上进行跳跃建立索引,并通过随机的方式决定下层节点是否要建立上层索引,使索引的节点尽可能随机离散。通过多级的跳跃节点,跳跃表能够快速的查找到对应节点,大大减少比较次数,和红黑树相比,跳跃表的结构十分简单,代码实现更为简单。一个简单的跳跃表如图所示:
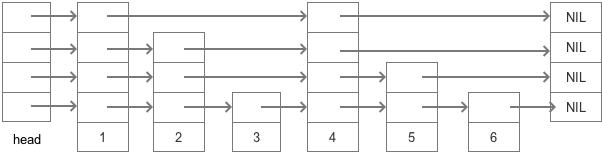 通过如图所示的多级节点,在整个集合特别大的时候,这样的跳跃节点就能大大减少查找时遍历的次数。
通过如图所示的多级节点,在整个集合特别大的时候,这样的跳跃节点就能大大减少查找时遍历的次数。
更详细的定义和数据结构算法解析这里就不多说了,本文主要是关注 redis 的实现
redis的实现
结构体定义
typedef struct zskiplistNode { // 跳跃表节点
robj *obj; // redis对象
double score; // 分值
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned int span; // 跨度
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length; // 跳跃表长度
int level; // 目前跳跃表的最大层数节点
} zskiplist;
redis 的跳跃表是一个双向的链表,并且在zskiplist结构体中保存了跳跃表的长度和头尾节点,方便从头查找或从尾部遍历。
跳跃表创建及插入
跳跃表的创建就是一些基本的初始化操作,需要注意的是 redis 的跳跃表最大层数为32,是为了能够足够支撑优化2^32个元素的查找。假设每个元素出现在上一层索引的概率为0.5,每个元素出现在第n层的概率为1/2^n,所以当有2^n个元素时,需要n层索引保证查询时间复杂度为O(logN)。
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */ // 跳跃表最大层数
zskiplistNode *zslCreateNode(int level, double score, robj *obj) { // 跳跃表节点创建
zskiplistNode *zn = zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->obj = obj;
return zn;
}
zskiplist *zslCreate(void) { // 跳跃表创建
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL); // 创建头结点
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) { // 初始化头结点
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
redis 的跳跃表出现在上层索引节点的概率为0.25,在这样的概率下跳跃表的查询效率会略大于O(logN),但是索引的存储内存却能节省一半。
#define ZSKIPLIST_P 0.25 // 跳跃表节点上升概率
int zslRandomLevel(void) { // 跳跃表获取随机level值 越大的数出现的几率越小
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) // 每往上提一层的概率为4分之一
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj) { // 跳跃表zset节点插入
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) { // 获取带插入节点的位置
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
compareStringObjects(x->level[i].forward->obj,obj) < 0))) { // 如果当前节点分支小于带插入节点
rank[i] += x->level[i].span; // 记录各层x前一个节点的索引跨度
x = x->level[i].forward; // 查找一下个节点
}
update[i] = x; // 记录各层x的前置节点
}
level = zslRandomLevel(); // 获取当前节点的level
if (level > zsl->level) { // 如果level大于当前skiplist的level 将大于部分的header初始化
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,obj); // 创建新节点
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward; // 建立x节点索引
update[i]->level[i].forward = x; // 将各层x的前置节点的后置节点置为x
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); // 计算x节点各层索引跨度
update[i]->level[i].span = (rank[0] - rank[i]) + 1; // 计算x前置节点的索引跨度
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) { // 如果level小于zsl的level
update[i]->level[i].span++; // 将x前置节点的索引跨度加一
}
x->backward = (update[0] == zsl->header) ? NULL : update[0]; // 设置x前置节点
if (x->level[0].forward)
x->level[0].forward->backward = x; // 设置x后面节点的前置节点
else
zsl->tail = x;
zsl->length++; // length+1
return x;
}
一个简单的 zsl 的结构体图如下:
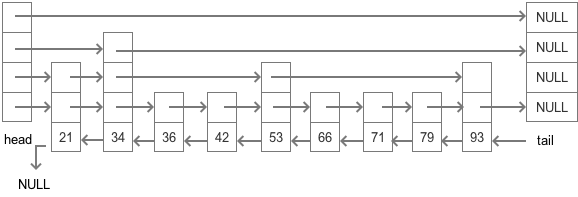
跳跃表的结构体定义在service.h中,api定义在z_set.c中。除了增删改查外,reidis还提供了跳跃表的各种Range操作api,可以自行查看其实现细节。
总结一波
- 跳跃表是一种有序的链表,持有多层索引,利用空间换取时间,平均查找效率为O(logN)
- redis 的跳跃表底层为双向链表,并持有尾指针方便从尾遍历
- reids 的跳跃表最大索引层数为32层,用于支持2^32个元素的索引建立
- 出于节省内存的目的,redis 的跳跃表每个元素到上一层索引的概率为0.25