近来在研读redis3.2.9的源码,虽然网上已有许多redis的源码解读文章,但大都不成系统,且纸上学来终觉浅,遂有该系列博文。部分知识点参照了黄建宏的《Redis设计与实现》。
前言
本文探究的数据结构并不是 redis 对外暴露的5种数据结构,而是redis内部使用的基础数据结构,这些基础的数据结构 redis 不仅和 redisObj 一起构成了对外暴露的5种数据结构,还被运用于 redis 内部的各种存储和逻辑交互,支撑起了 redis 的运行。
redis 的基础数据结构主要有以下7种:
- SDS(simple dynamic string):简单动态字符串
- ADList(A generic doubly linked list):双向链表
- dict(Hash Tables):字典
- intset:整数集合
- ziplist:压缩表
- quicklist:快速列表(双向链表和压缩表二合一的复杂数据结构)
- skiplist:跳跃链表
ziplist
ziplist是 redis 节省内存的典型例子之一,这个数据结构通过特殊的编码方式将数据存储在连续的内存中。在3.2之前是list的基础数据结构之一,在3.2之后被quicklist替代。但是仍然是zset底层实现之一。
定义
压缩表没有数据结构代码定义,完全是通过内存的特殊编码方式实现的一种紧凑存储数据结构。我们可以通过ziplist的初始化函数和操作api来倒推其内存分布。
首先看ziplist的一些宏定义以及初始化函数:
#define ZIP_END 255
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) // 获取ziplist的bytes指针
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) // 获取ziplist的tail指针
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) // 获取ziplist的len指针
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) // ziplist头大小
#define ZIPLIST_END_SIZE (sizeof(uint8_t)) // ziplist结束标志位大小
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) // 获取第一个元素的指针
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) // 获取最后一个元素的指针
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1) // 获取结束标志位指针
unsigned char *ziplistNew(void) { // 创建一个压缩表
unsigned int bytes = ZIPLIST_HEADER_SIZE+1; // zip头加结束标识位数
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); // 大小端转换
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0; // len赋值为0
zl[bytes-1] = ZIP_END; // 结束标志位赋值
return zl;
}
通过上面的源码,我们不难看出ziplist的头是由两个unint32_t和一个unint16_t组成。这3个数字分别保存是ziplist的内存占用、元素数量和最后一个元素的偏移量。除此之外,ziplist还包含一个结束标识,用常量255表示。整个ziplist描述内容占用了11个字节。初始化后的内存图如下:
 为了方便操作,redis 定义了一个
为了方便操作,redis 定义了一个zlentry结构体用于内部函数使用:
typedef struct zlentry { // 压缩列表节点
unsigned int prevrawlensize, prevrawlen; // prevrawlen是前一个节点的长度,prevrawlensize是指prevrawlen的大小,有1字节和5字节两种
unsigned int lensize, len; // len为当前节点长度 lensize为编码len所需的字节大小
unsigned int headersize; // 当前节点的header大小
unsigned char encoding; // 节点的编码方式
unsigned char *p; // 指向节点的指针
} zlentry;
void zipEntry(unsigned char *p, zlentry *e) { // 根据节点指针返回一个enrty
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen); // 获取prevlen的值和长度
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len); // 获取当前节点的编码方式、长度等
e->headersize = e->prevrawlensize + e->lensize; // 头大小
e->p = p;
}
数据编码
每个entry可以存储一个整数或一个字节数组。为了节省内存,redis 对不同类型,不同大小的数据采用了不同的编码方式,下面是不同数据类型的编码方式:
#define ZIP_STR_06B (0 << 6) // 小于63字节字节数组
#define ZIP_STR_14B (1 << 6) // 小于2^14-1字节的字节数组
#define ZIP_STR_32B (2 << 6) // 小于2^32-1字节的字节数组
#define ZIP_INT_16B (0xc0 | 0<<4) // int16_t整数
#define ZIP_INT_32B (0xc0 | 1<<4) // int32_t整数
#define ZIP_INT_64B (0xc0 | 2<<4) // int64_t整数
#define ZIP_INT_24B (0xc0 | 3<<4) // 3个字节长度的整数
#define ZIP_INT_8B 0xfe // 1个字节长度的整数
#define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */ // 直接编码存储的最小值
#define ZIP_INT_IMM_MAX 0xfd /* 11111101 */ // 直接编码存储方式的最大值
#define INT24_MAX 0x7fffff // 3字节整数最大值 2^24-1
#define INT24_MIN (-INT24_MAX - 1) // 3字节整数最小值 -2^24
int zipTryEncoding(unsigned char *entry, unsigned int entrylen, long long *v, unsigned char *encoding) { // 整数数据编码
long long value;
if (entrylen >= 32 || entrylen == 0) return 0;
if (string2ll((char*)entry,entrylen,&value)) { // 尝试将字节数组转换为整数
/* Great, the string can be encoded. Check what's the smallest
* of our encoding types that can hold this value. */
if (value >= 0 && value <= 12) {
*encoding = ZIP_INT_IMM_MIN+value; // 编码和具体的值共同占用一个字节,无需单独存储value值
} else if (value >= INT8_MIN && value <= INT8_MAX) {
*encoding = ZIP_INT_8B;
} else if (value >= INT16_MIN && value <= INT16_MAX) {
*encoding = ZIP_INT_16B;
} else if (value >= INT24_MIN && value <= INT24_MAX) { // redis自定义的3字节整数
*encoding = ZIP_INT_24B;
} else if (value >= INT32_MIN && value <= INT32_MAX) {
*encoding = ZIP_INT_32B;
} else {
*encoding = ZIP_INT_64B;
}
*v = value;
return 1;
}
return 0;
}
unsigned int zipEncodeLength(unsigned char *p, unsigned char encoding, unsigned int rawlen) { // 存储数据编码,返回编码长度
unsigned char len = 1, buf[5];
if (ZIP_IS_STR(encoding)) { // 如果是字节数组
/* Although encoding is given it may not be set for strings,
* so we determine it here using the raw length. */
if (rawlen <= 0x3f) { // 小于等于63个字节的字节数组,用一个字节进行存储
if (!p) return len; // 如果p为NULL,说明只是单纯需要获取编码长度
buf[0] = ZIP_STR_06B | rawlen;
} else if (rawlen <= 0x3fff) { // 小于等于16383(2^14-1)个字节,用2个字节进行存储编码
len += 1;
if (!p) return len;
buf[0] = ZIP_STR_14B | ((rawlen >> 8) & 0x3f);
buf[1] = rawlen & 0xff;
} else { // 小于2^32-1个字节 用5个字节进行编码
len += 4;
if (!p) return len;
buf[0] = ZIP_STR_32B;
buf[1] = (rawlen >> 24) & 0xff;
buf[2] = (rawlen >> 16) & 0xff;
buf[3] = (rawlen >> 8) & 0xff;
buf[4] = rawlen & 0xff;
}
} else {
/* Implies integer encoding, so length is always 1. */
if (!p) return len;
buf[0] = encoding;
}
/* Store this length at p */
memcpy(p,buf,len); // 将编码存储到p指针中
return len; // 返回编码长度
}
通过zipEncodeLength和zipTryEncoding两个函数以及宏定义,我们可以将ziplist中数据的编码方式做一个总结:
整数编码
| 编码 | 编码长度 | content保存数据范围 |
|---|---|---|
| 1111xxxx | 1字节 | 整数值值在[0,12]区间, 该编码方式单独不保存value,而是将value直接保存到后4位 |
| 11111110 | 1字节 | uint8_t类型整数 |
| 11000000 | 1字节 | uint16_t类型整数 |
| 11110000 | 1字节 | 24位整数,[-2^24,2^24-1]区间 |
| 11010000 | 1字节 | uint32_t类型整数 |
| 11100000 | 1字节 | uint64_t类型整数 |
字符串编码
| 编码 | 编码长度 | content保存数据范围 |
|---|---|---|
| 00xxxxxx | 1字节 | 长度小于等于63的字节数组,后6位用于保存字节数组长度 |
| 01xxxxxx xxxxxxxx | 2字节 | 长度小于等于16383(2^14-1)的字节数组,除最高两位都是用来存储字节数组长度 |
| 10xxxxxx xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx | 5字节 | 长度小于等于2^32-1的字节数组,除最高两位都是用来存储字节数组长度 |
push
有了一个初始化后的ziplist,就可以往里添加数据了,以push函数为例对ziplist的插入过程做一个解析,顺便把ziplist的完整数据结构做一个整理:
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) { // push
unsigned char *p;
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
return __ziplistInsert(zl,p,s,slen);
}
push的方式分为头尾两种,主体还是要看__ziplistInsert函数:
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) { // 插入
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) { // 如果不是在尾部插入
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); // 获取prevlen
} else { // 在尾部插入
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl); // 获取最后一个entry
if (ptail[0] != ZIP_END) { // 如果ziplist不为空
prevlen = zipRawEntryLength(ptail); // prevlen就是最后一个enrty的长度
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) { // 尝试对value进行整数编码
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding); // 数据长度
} else {
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
reqlen = slen; // 字符数组长度
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipPrevEncodeLength(NULL,prevlen); // 获取pre编码长度
reqlen += zipEncodeLength(NULL,encoding,slen); // 获取编码长度
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0; // 如果不在尾部插入,需要判断当前prelen大小是否够用
if (nextdiff == -4 && reqlen < 4) { // 如果当前节点prelen为5个字节或1个字节已经够用
nextdiff = 0;
forcelarge = 1;
}
/* Store offset because a realloc may change the address of zl. */
offset = p-zl; // 记录偏移量,因为realloc可能会改变ziplist的地址
zl = ziplistResize(zl,curlen+reqlen+nextdiff); // 重新申请内存
p = zl+offset; // 拿到p指针
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) { // 不是在尾部插入
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff); // 通过内存拷贝将原有数据后移,因为移动前后内存地址有重叠需要用memmove
/* Encode this entry's raw length in the next entry. */
if (forcelarge)
zipPrevEncodeLengthForceLarge(p+reqlen,reqlen); // 当下一个节点的prelen空间已经够用时,不需要压缩,防止连锁更新
else
zipPrevEncodeLength(p+reqlen,reqlen); // 将reqlen保存到后一个节点中
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen); // 更新tail值
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) { // 如果下一个节点的prelen扩展了需要加上nextdiff
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else { // 如果是在尾部插入直接更新tail_offset
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
if (nextdiff != 0) { // 连锁更新
offset = p-zl; // 记录offset预防地址变更
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
p += zipPrevEncodeLength(p,prevlen); // 记录prelen
p += zipEncodeLength(p,encoding,slen); // 记录encoding和len
if (ZIP_IS_STR(encoding)) { // 保存字符串
memcpy(p,s,slen);
} else { // 保存数字
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1); // ziplist的len加1
return zl;
}
一个完整的插入流程大致是这样的:
- 获取p指针的
prelen - 根据
prelen值计算当前带插入节点的reqlen - 校验p指针对应的节点的
prelen是否够reqlen使用,不够需要扩展,够不进行压缩 - 重新申请内存,如果不是在尾部插入需要将对应数据后移
- 更新
ziplist的tailoffset值 - 尝试进行连锁更新
- 保存当前节点,分表保存prevlen、encoding、对应内容
ziplist的len加1
通过对push的梳理,entry的内存分布就很清晰了:
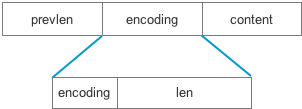
- 每个entry都是由一个prelen、encoding和content组成
- prelen保存着前一个节点长度,前一个节点长度小于254时采用一个字节编码,否则采用5个字节
- encoding保存着当前节点的编码方式和数据长度
- content保存着entry的具体数据,可以是一个字节数组或整数,如果是整数且在0-12之间不保存content
完整的ziplist的内存分布情况就是<zipbytes><tailoffset><ziplen><prelen1><encoding1><contennt1><prelen2><encoding2><contennt2>...<zipend>:
 通过连续的内存和上述编码方式,
通过连续的内存和上述编码方式,ziplist可以很方便的拿到头尾节点;由于每个节点都保存了前一个节点的长度,因此可以通过尾节点很方便的利用内存偏移进行遍历;相比链表或hash表大大压缩了内存;最主要这个数据结构的大部分场景都是pop或push,因此在查找和中间插入场景下的时间复杂度提升也是可以接受的。
连锁更新
由于每个节点都保存着前一个节点的长度,并且 redis 出于节省内存的考量,针对254这个分界点上下将prelen的长度分别设为1和5字节。因此当我们插入一个节点时,后一个节点的prelen可能就需要进行扩展;那么如果后一个节点原本的长度为253呢?由于prelen的扩展,导致再后一个节点也需要进行扩展。在最极端情况下会将整个ziplist都进行更新。
在push的代码中可以看到如果当前节点的prelen字段进行了扩展,会调用__ziplistCascadeUpdate进行连锁更新:
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) { // 连锁更新
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize;
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
while (p[0] != ZIP_END) { // 遍历所有节点
zipEntry(p, &cur); // 获取当前节点
rawlen = cur.headersize + cur.len; // 当前节点长度
rawlensize = zipPrevEncodeLength(NULL,rawlen); // 当前节点所需要的prelen大小
/* Abort if there is no next entry. */
if (p[rawlen] == ZIP_END) break; // 没有下一个节点
zipEntry(p+rawlen, &next); // 获取上一个节点
/* Abort when "prevlen" has not changed. */
if (next.prevrawlen == rawlen) break; // prelen没变直接break
if (next.prevrawlensize < rawlensize) { // 只有当需要扩展的时候才会触发连锁更新
/* The "prevlen" field of "next" needs more bytes to hold
* the raw length of "cur". */
offset = p-zl; // 记录偏移量,预防内存地址变更
extra = rawlensize-next.prevrawlensize;
zl = ziplistResize(zl,curlen+extra); // 重新申请内存
p = zl+offset;
/* Current pointer and offset for next element. */
np = p+rawlen;
noffset = np-zl;
/* Update tail offset when next element is not the tail element. */
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) { // 更新tailoffset
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
/* Move the tail to the back. */
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1); // 内存拷贝
zipPrevEncodeLength(np,rawlen); // 记录新的prelen
/* Advance the cursor */
p += rawlen; // 检查下一个节点
curlen += extra; // 更新curlen
} else { // 小于之前的size或者相等都并不会引起连锁更新
if (next.prevrawlensize > rawlensize) {
zipPrevEncodeLengthForceLarge(p+rawlen,rawlen); // 当原有的prelensize大于当前所需时,不进行收缩直接赋值减少后续连锁更新的可能性
} else {
zipPrevEncodeLength(p+rawlen,rawlen);
}
/* Stop here, as the raw length of "next" has not changed. */
break; // 直接结束连锁更新
}
}
return zl;
}
可以看到ziplist的连锁更新是一个一个节点进行校验,直到遍历完整个ziplist或遇到不需要更新的节点为止。
个人觉得先遍历完,记录需要变更的节点最后统一处理会好一点。但是对应的代码复杂度和空间复杂度也会高一点,需要开辟更多的空间保存临时节点数据,但是realloc次数由最少一次优化到1次。不过出现极端场景的概率也比较小,也许 redis 正是出于这一点考量直接遍历一个一个节点进行处理吧。
除了插入新的节点可能会引起连锁更新,删除节点也可能会引起连锁更新。
总结一波
又到了总结的时候了,一些查找和pop方法就不做过多详解了,具体的源码在ziplist.h和ziplist.c文件中:
ziplist是 redis 为了节省内存,提升存储效率自定义的一种紧凑的数据结构ziplist保存着尾节点的偏移量,可以方便的拿到头尾节点- 每一个
entry都保存着前一个entry的长度,可以很方便的从尾遍历 - 每个
entry中都可以保存一个字节数组或整数,不同类型和大小的数据有不同的编码方式 - 添加和删除节点可能会引发连锁更新,极端情况下会更新整个
ziplist,但是概率很小