近来在研读redis3.2.9的源码,虽然网上已有许多redis的源码解读文章,但大都不成系统,且纸上学来终觉浅,遂有该系列博文。部分知识点参照了黄建宏的《Redis设计与实现》。
前言
本文探究的数据结构并不是 redis 对外暴露的5种数据结构,而是redis内部使用的基础数据结构,这些基础的数据结构 redis 不仅和 redisObj 一起构成了对外暴露的5种数据结构,还被运用于 redis 内部的各种存储和逻辑交互,支撑起了 redis 的运行。
redis 的基础数据结构主要有以下7种:
- SDS(simple dynamic string):简单动态字符串
- ADList(A generic doubly linked list):双向链表
- dict(Hash Tables):字典
- intset:整数集合
- ziplist:压缩表
- quicklist:快速列表(双向链表和压缩表二合一的复杂数据结构)
- skiplist:跳跃链表
SDS
redis 没有直接使用c语言的字符串,而是自己定义了一个字符串数据结构:SDS(simple dynamic string)作为默认的字符串。我们设置的所有键值基本都是SDS。
那么为何 redis 要自己定义一个字符串数据结构呢?我们看看SDS的定义以及他和C语言字符串的区别就清楚了。
SDS的定义
3.2和3.0的差别
sds在 redis 3.2版本做了较大的变动,这里就简单顺便介绍一下两个版本的差别。在3.2版本以前SDS只有一种数据结构,到了3.2版本以后SDS根据存储的内容会选择不同的数据结构,以到达节省内存的效果!
// 3.0及以前
struct sdshdr {
// 记录buf数组中已使用字节数量
unsigned int len;
// 记录buf数组中未使用的字节数量
unsigned int free;
// 字节数组,存储字符串
char buf[];
};
// >=3.2
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
可以看到,在3.2以后的版本,redis 的SDS分为了5种数据结构,分别应对不同长度的字符串需求,具体的类型选择如下。
static inline char sdsReqType(size_t string_size) { // 获取类型
if (string_size < 1<<5) // 32
return SDS_TYPE_5;
if (string_size < 1<<8) // 256
return SDS_TYPE_8;
if (string_size < 1<<16) // 65536 64k
return SDS_TYPE_16;
if (string_size < 1ll<<32) // 4294967296 4GB
return SDS_TYPE_32;
return SDS_TYPE_64;
}
__attribute__ ((__packed__))是什么呢?首先就要了解编译器内存对齐的优化策略:
struct的分配的内存是内部最大元素的整数倍
如果内存不对齐,cpu的的内存访问速度会大大下降,至于内存对齐的原理这里就不做赘述了,有兴趣可以自行google或百度。
而__attribute__ ((__packed__))这个声明就是用来告诉编译器取消内存对齐优化,按照实际的占用字节数进行对齐,效果如下:
printf("%ld\n", sizeof(struct sdshdr8)); // 3
printf("%ld\n", sizeof(struct sdshdr16)); // 5
printf("%ld\n", sizeof(struct sdshdr32)); // 9
printf("%ld\n", sizeof(struct sdshdr64)); // 17
通过加上__attribute__ ((__packed__))声明,sdshdr16节省了1个字节,sdshdr32节省了3个字节,sdshdr64节省了7个字节。
但是内存对齐怎么办呢,不能为了一点内存大大拖慢cpu的寻址效率啊?redis 通过自己在malloc等c语言内存分配函数上封装了一层zmalloc,将内存分配收敛,并解决了内存对齐的问题。在内存分配前有这么一段代码:
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1)); \ // 确保内存对齐!
这段代码写的比较抽象,简而言之就是先判断当前要分配的_n个内存是否是long类型的整数倍,如果不是就在_n的基础上加上内存大小差值,从而达到了内存对齐的保证。
SDS数据结构解读
扯了一大堆有点偏题了,回到正题,以 redis 3.2.9的sdshdr8为例来解读一下这个数据结构:
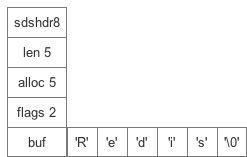
len记录当前字节数组的长度(不包括\0),使得获取字符串长度的时间复杂度由O(N)变为了O(1)alloc记录了当前字节数组总共分配的内存大小(不包括\0)flags记录了当前字节数组的属性、用来标识到底是sdshdr8还是sdshdr16等buf保存了字符串真正的值以及末尾的一个\0
整个SDS的内存是连续的,统一开辟的。为何要统一开辟呢?因为在大多数操作中,buf内的字符串实体才是操作对象。如果统一开辟内存就能通过buf头指针进行寻址,拿到整个struct的指针,而且通过buf的头指针减一直接就能获取flags的值,骚操作代码如下!
// flags值的定义
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
// 通过buf获取头指针
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
// 通过buf的-1下标拿到flags值
unsigned char flags = s[-1];
至于buf末尾的\0是为了复用string.h中部分字符串操作函数。
创建SDS
这块比较直白易懂,直接show源码:
sds sdsnewlen(const void *init, size_t initlen) { // 创建sds
void *sh;
sds s; // 指向字符串头指针
char type = sdsReqType(initlen);
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; // 如果是空字符串直接使用SDS_TYPE_8,方便后续拼接
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1); // 分配空间大小为 sdshdr大小+字符串长度+1
if (!init)
memset(sh, 0, hdrlen+initlen+1); // 初始化内存空间
if (sh == NULL) return NULL;
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1; // 获取flags指针
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS); // sdshdr5的前5位保存长度,后3位保存type
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s); // 获取sdshdr指针
sh->len = initlen; // 设置len
sh->alloc = initlen; // 设置alloc
*fp = type; // 设置type
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen); // 内存拷贝字字符数组赋值
s[initlen] = '\0'; // 字符数组最后一位设为\0
return s;
}
由于sdshdr5的只用来存储长度为32字节以下的字符数组,因此flags的5个bit就能满足长度记录,加上type所需的3bit,刚好为8bit一个字节,因此sdshdr5不需要单独的len记录长度,并且只有32个字节的存储空间,动态的变更内存余地较小,所以 redis 直接不存储alloc,当sdshdr5需要扩展时会直接变更成更大的SDS数据结构。
除此之外,SDS都会多分配1个字节用来保存'\0'。
SDS拼接
SDS的拼接函数sdscatlen和C语言的strcat有着很大的出入,直接上代码:
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s); // 获取当前字符串长度
s = sdsMakeRoomFor(s,len); // 重点!
if (s == NULL) return NULL;
memcpy(s+curlen, t, len); // 内存拷贝
sdssetlen(s, curlen+len); // 设置sds->len
s[curlen+len] = '\0'; // 在buf的末尾追加一个\0
return s;
}
可以看到除了调用了一下sdsMakeRoomFor以外,就是正常的内存拷贝和设置使用长度等等,那么就来看看sdsMakeRoomFor好了:
sds sdsMakeRoomFor(sds s, size_t addlen) { // 确保sds字符串在拼接时有足够的空间
void *sh, *newsh;
size_t avail = sdsavail(s); // 获取可用长度
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s); // 获取字符串长度 O(1)
sh = (char*)s-sdsHdrSize(oldtype); // 获取当前sds指针
newlen = (len+addlen); // 分配策略 SDS_MAX_PREALLOC=1024*1024=1M
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2; // 如果拼接后的字符串小于1M,就分配两倍的内存
else
newlen += SDS_MAX_PREALLOC; // 如果拼接后的字符串大于1M,就分配多分配1M的内存
type = sdsReqType(newlen); // 获取新字符串的sds类型
if (type == SDS_TYPE_5) type = SDS_TYPE_8; // 如果type为SDS_TYPE_5直接优化成SDS_TYPE_8
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1); // 类型没变在原有基础上realloc
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1); // 类型发生变化需要重新malloc
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1); // 将老字符串拷贝到新的内存快中
s_free(sh); // 释放老的sds内存
s = (char*)newsh+hdrlen;
s[-1] = type; // 设置sds->flags
sdssetlen(s, len); // 设置sds->len
}
sdssetalloc(s, newlen); // 设置sds->alloc
return s;
}
该方法是用来确保SDS字符串在拼接时有足够的空间,如果空间不够就会重新分配内存,但是分配内存并不是只分配当下要用的内存,而是采用了冗余的预分配内存,通过源码可以看到内存的预分配策略主要有两种:
- 拼接后的字符串长度不超过1M,分配两倍的内存
- 拼接够的字符串长度超过1M,多分配1M的内存
通过这两种策略,在字符串拼接时会预分配一部分内存,下次拼接的时候就可能不再需要进行内存分配了,将原本N次字符串拼接需要N次内存重新分配的次数优化到最多需要N次,是典型的空间换时间的做法。
当然,如果新的字符串长度超过了原有字符串类型的限定那么还会涉及到一个重新生成sdshdr的过程。
还有一个细节需要注意,由于sdshrd5并不存储alloc值,因此无法获取sdshrd5的可用大小,如果继续采用sdshrd5进行存储,在之后的拼接过程中每次都还是要进行内存重分配。因此在发生拼接行为时,sdshrd5会被直接优化成sdshrd8。
SDS惰性空间释放
在SDS的字符串缩短操作中,多余出来的空间并不会直接释放,而是保留这部分空间,待以后再用。以sdstrim为例:
sds sdstrim(sds s, const char *cset) { // sds trim操作
char *start, *end, *sp, *ep;
size_t len;
sp = start = s;
ep = end = s+sdslen(s)-1;
while(sp <= end && strchr(cset, *sp)) sp++; // 从头遍历
while(ep > sp && strchr(cset, *ep)) ep--; // 从尾部遍历
len = (sp > ep) ? 0 : ((ep-sp)+1);
if (s != sp) memmove(s, sp, len); // 内存拷贝
s[len] = '\0';
sdssetlen(s,len); // 重新设置sds->len
return s;
}
将A. :HelloWroldA.:进行sdstrim(s,"Aa. :");后,如下图所示:
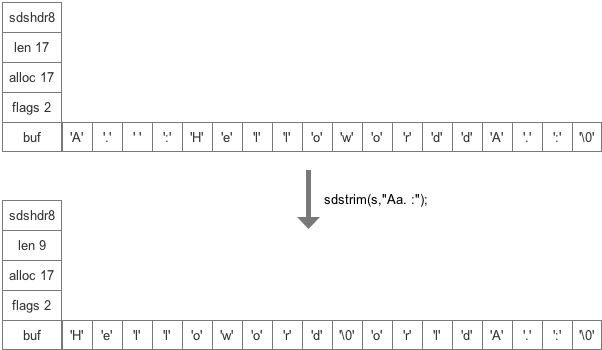 可以看到内存空间并没有被释放,甚至空闲的空间都没有被置空。由于SDS是通过
可以看到内存空间并没有被释放,甚至空闲的空间都没有被置空。由于SDS是通过len值标识字符串长度,因此SDS完全不需要受限于c语言字符串的那一套\0结尾的字符串形式。在后续需要拼接扩展时,这部分空间也能够再次被利用起来,降低了内存重新分配的概率。
当然,SDS也提供了真正的释放空间的方法,以供真正需要释放空闲内存时使用。
总结一波
- redis 3.2之后,针对不同长度的字符串引入了不同的SDS数据结构,并且强制内存对齐1,将内存对齐交给统一的内存分配函数,从而达到节省内存的目的
- SDS的字符串长度通过
sds->len来控制,不受限于C语言字符串\0,可以存储二进制数据,并且将获取字符串长度的时间复杂度降到了O(1) - SDS的头和
buf字节数组的内存是连续的,可以通过寻址方式获取SDS的指针以及flags值 - SDS的拼接扩展有一个内存预分配策略,用空间减少每次拼接的内存重分配可能性
- SDS的缩短并不会真正释放掉对应空闲空间
- SDS分配内存都会多分配1个字节用来在
buf的末尾追加一个\0,在部分场景下可以和C语言字符串保证同样的行为甚至复用部分string.h的函数
其他的一些细节或者操作函数这里就不做详解了,如果感兴趣可以自行刷一波源码,SDS相关的源码在sds.h和sds.c文件中。